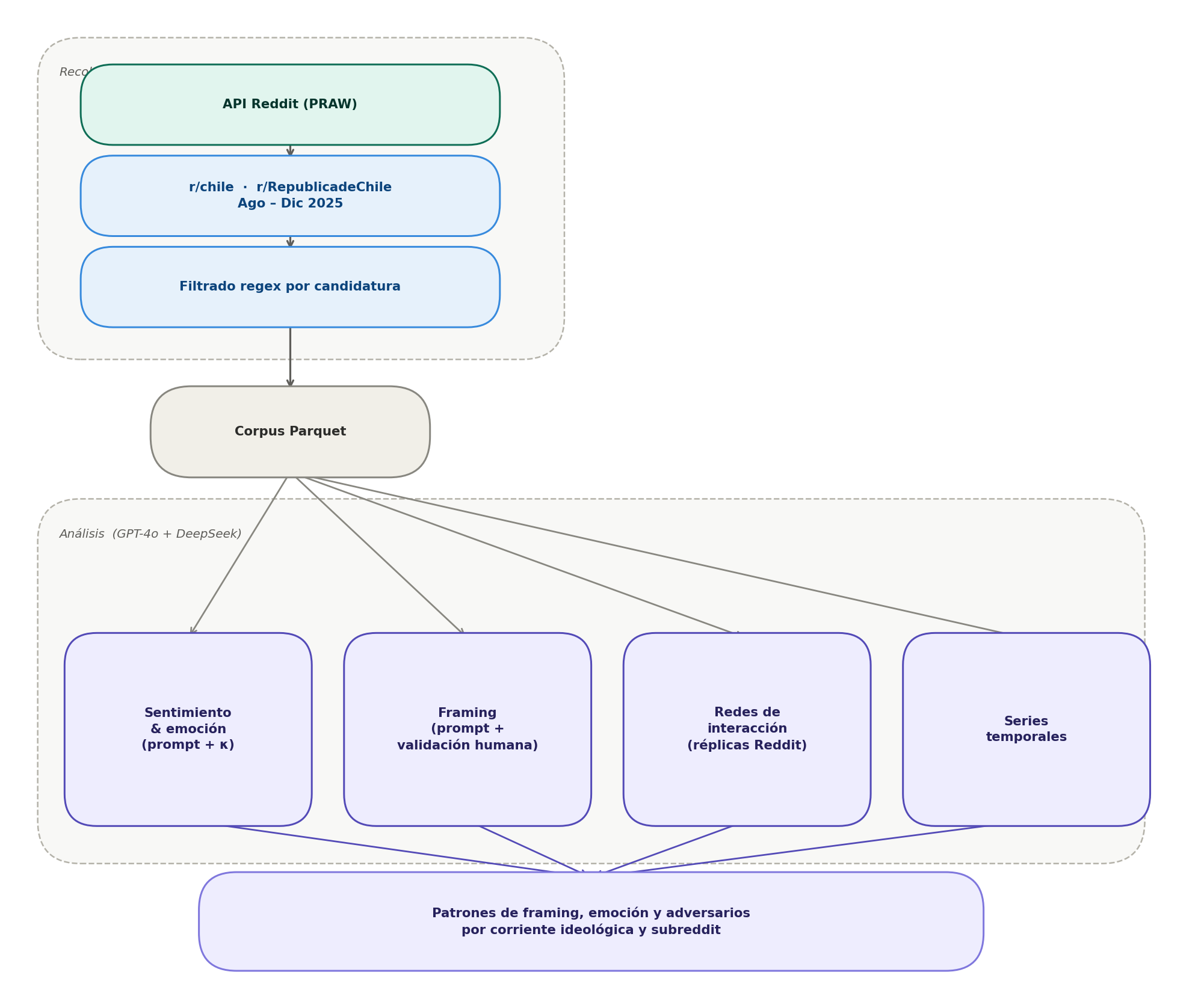
4 Diseño metodológico
Análisis textual longitudinal de la contestación discursiva en las elecciones presidenciales de 2025 en Chile
4.1 Diseño de investigación
Esta investigación adopta un diseño longitudinal observacional basado en datos digitales generados por usuarios (user-generated content). El carácter longitudinal permite capturar la evolución del debate político a lo largo del ciclo electoral, identificando tendencias, puntos de inflexión y dinámicas de cambio. El carácter observacional preserva las propiedades naturales de la interacción en las plataformas estudiadas, sin intervención experimental.
Metodológicamente, la investigación se inscribe en la ciencia social computacional [@Lazer2009; @Salganik2019]: integra técnicas de procesamiento de datos a gran escala con marcos teóricos y preguntas sustantivas de las ciencias sociales. El diseño combina componentes descriptivos —caracterizar la conversación política en Reddit durante el período estudiado— con componentes explicativos, orientados a identificar los factores y mecanismos que dan cuenta de los patrones observados.
4.2 Reddit como plataforma de análisis
Reddit es una plataforma de agregación de contenido y discusión organizada en comunidades temáticas denominadas subreddits, cada una con sus propias normas, moderadores y cultura discursiva. A diferencia de plataformas organizadas en torno a redes de seguidores o amistades, Reddit estructura la participación en torno a intereses y temas compartidos, lo que favorece conversaciones más extensas y argumentadas que en otros entornos digitales.
Su arquitectura de comentarios anidados (threaded discussions) permite seguir el desarrollo de argumentos y contraargumentos en múltiples niveles, haciendo visible la estructura deliberativa del debate. El sistema de votación (upvotes/downvotes) ofrece un indicador de resonancia comunitaria, y la persistencia de los hilos habilita el análisis longitudinal de conversaciones en desarrollo.
Los usuarios operan bajo seudónimos no vinculados a su identidad real, lo que puede facilitar la expresión de posiciones polémicas. Las comunidades son autogobernadas: cada subreddit define sus propias reglas de participación, generando culturas discursivas distintivas que hacen de la comparación entre comunidades un ejercicio analíticamente valioso.
En el contexto chileno, dos subreddits concentran la discusión política nacional:
- r/chile: Comunidad generalista sobre temas chilenos, con mayor volumen de usuarios y diversidad temática. Ha tendido históricamente hacia posiciones de centro-izquierda, aunque con presencia de voces diversas.
- r/RepublicadeChile: Comunidad surgida como escisión de r/chile, con políticas de moderación más permisivas y una composición ideológica tendiente a la derecha. Tolera discursos más confrontacionales y concentra usuarios críticos de la moderación de r/chile.
Esta dualidad constituye un caso comparativo de valor: permite examinar cómo una misma controversia política es procesada de manera diferenciada según la cultura discursiva de la comunidad.
4.3 Recolección de datos mediante la API de Reddit
Procedimiento técnico
Los datos fueron extraídos mediante la API pública de Reddit utilizando la librería PRAW (Python Reddit API Wrapper). Esta aproximación —distinta del web scraping no autorizado— accede de forma estructurada a contenido público respetando los límites de uso establecidos por la plataforma y garantizando la trazabilidad y reproducibilidad del proceso.
Período de recolección y fases del ciclo electoral
La recolección abarcó cinco meses, del 1 de agosto al 31 de diciembre de 2025, cubriendo las siguientes fases del ciclo electoral:
| Período | Fase electoral |
|---|---|
| Agosto – octubre 2025 | Emergencia de candidaturas, posicionamiento inicial, primeras definiciones programáticas |
| Noviembre – diciembre 2025 | Escalamiento de campaña, consolidación electoral, estructuración del debate público |
Estrategia de extracción incremental
El proceso fue incremental y acumulativo, ejecutado en múltiples iteraciones que: (1) recuperaban los posts más recientes de cada subreddit (250–1.000 posts por ejecución); (2) descargaban el árbol completo de comentarios mediante replace_more(limit=None) para capturar todos los niveles de anidación; (3) integraban nuevos datos con extracciones previas en archivos Parquet; y (4) eliminaban duplicados mediante el identificador único nativo de Reddit (post_id), que garantiza unicidad por diseño de la plataforma.
Contenido extraído y filtrado temático
Para cada publicación dentro del rango temporal se extrajeron dos niveles:
Posts: título, cuerpo (selftext), autor, fecha, puntuación, número de comentarios y flair temático.
Comentarios: cuerpo del comentario, autor, fecha, puntuación e identificador del comentario al que responde.
El filtrado temático se realizó mediante expresiones regulares que detectan menciones de las cuatro candidaturas de interés, manejando variaciones ortográficas (acentuación, nombres completos vs. apellidos, apodos y errores tipográficos frecuentes):
| Candidatura | Corriente ideológica | Patrones de búsqueda |
|---|---|---|
| Evelyn Matthei | Derecha tradicional | matthei, matei, evelyn |
| José Antonio Kast | Derecha radical-conservadora | kast, jose antonio kast, jak |
| Johannes Kaiser | Derecha libertaria | kaiser, johannes, jkaiser |
| Jeannette Jara | Izquierda-PC | jara, jeannette, jeanette |
Esta selección permite analizar tanto la competencia intra-derecha entre tres corrientes como la convergencia discursiva frente al adversario ideológico común (ver Tabla 4.1).
4.4 Consideraciones éticas
La investigación se rige por principios establecidos para la investigación con datos digitales [@Salganik2019; @Zimmer2017]:
Datos públicos: Todo el contenido recolectado proviene de espacios públicos de Reddit. No se accedió a mensajes privados ni a información restringida.
Privacidad: El análisis no reporta identificadores individuales ni busca vincular cuentas con identidades reales. Los ejemplos citados son anonimizados cuando resulta pertinente.
No intervención: La investigación no actúa sobre las comunidades estudiadas ni expone a sus miembros a riesgos adicionales; el foco es el análisis de dinámicas colectivas.
Reproducibilidad: Los scripts de recolección y procesamiento están documentados para permitir la replicación del estudio respetando los términos de uso de la API.
4.5 Técnicas de análisis
El análisis combina la capacidad de procesamiento de modelos de lenguaje de gran escala con validación humana sistemática. Se utilizaron dos APIs de forma complementaria: GPT-4o (OpenAI) y DeepSeek, seleccionados por su capacidad de comprensión del español rioplatense y chileno, su desempeño en tareas de clasificación de texto político y la posibilidad de controlar los prompts con precisión. Ningún modelo reemplaza el juicio analítico: en todos los casos, las clasificaciones automatizadas son revisadas y validadas manualmente sobre muestras representativas antes de escalar al corpus completo.
Análisis de sentimiento y emociones
Cada fragmento del corpus fue procesado mediante prompts estructurados que solicitaban a los modelos clasificar: polaridad (positiva, negativa, neutra), intensidad emocional (baja, media, alta) y emoción predominante (alegría, miedo, ira, desprecio, indignación, esperanza). Los prompts incluían definiciones operacionales de cada categoría y ejemplos de calibración extraídos del propio corpus de Reddit chileno.
La clasificación automática fue validada mediante codificación manual de una muestra aleatoria estratificada por candidatura y subreddit, calculando coeficientes de acuerdo intercalificador (Cohen’s κ) para establecer umbrales de confiabilidad aceptables antes de aplicar el esquema al corpus completo.
Clasificación de marcos interpretativos (framing)
Para identificar los marcos interpretativos predominantes, se diseñaron prompts que solicitaban a los modelos asignar cada fragmento a uno o más de los marcos definidos teóricamente: económico, seguridad, identitario, institucional y medioambiental. Los prompts especificaban indicadores lingüísticos de cada marco y pedían justificación de la clasificación, lo que permitió refinar iterativamente las definiciones operacionales.
Al igual que en el análisis de sentimiento, las clasificaciones fueron validadas manualmente antes de escalar. Los casos de desacuerdo entre GPT-4o y DeepSeek fueron marcados para revisión humana prioritaria, convirtiendo la divergencia entre modelos en un indicador de ambigüedad analítica.
Análisis de redes de interacción
A partir de la estructura de respuestas anidadas de Reddit, se construyeron redes de réplica donde los nodos representan usuarios y las aristas representan relaciones de respuesta (comentario a comentario). El análisis de estas redes permite identificar subcomunidades discursivas, patrones de confrontación o cooperación entre usuarios de distintas orientaciones ideológicas, y la presencia de estructuras de cámara de eco en cada subreddit.
Análisis temporal
El diseño longitudinal habilita el análisis de series temporales de los indicadores de interés: volumen de menciones, tono emocional promedio y distribución de marcos temáticos semana a semana. Se identifican tendencias, ciclos y puntos de quiebre, así como correlaciones entre eventos externos (debates, declaraciones, controversias) y cambios en los patrones discursivos.
4.6 Corpus final y pipeline de procesamiento
Al cierre de la recolección (31 de diciembre de 2025), el corpus contiene todos los posts y sus árboles completos de comentarios publicados en r/chile y r/RepublicadeChile durante el período que mencionan al menos una de las cuatro candidaturas de interés, junto con sus metadatos asociados. La estructura del corpus permite análisis longitudinales, de red e interaccionales a lo largo del ciclo electoral completo.